
No dia a dia é alto o número de vezes que precisamos consultar informações no banco de dados e talvez nem nos damos conta do quanto fazemos isso.
Isto acontece com uma alta frequência quando, por exemplo, vamos ao supermercado, ao banco e em muitas outras das atividades do nosso cotidiano. Ou seja, toda vez que interagimos com um sistema ou um aplicativo de alguma forma estamos interagindo com o banco de dados.
Sabemos que interagir com o banco trazendo ou não um volume grande de dados, não é tão simples como parece e sabemos também dos problemas que enfrentamos com isso.
O maior problema é a demora que muitas vezes uma consulta pode ter. Quantas vezes nos deparamos com uma tela que demora para abrir, uma grid que leva um tempo grande para carregar ou um relatório que não traz as informações de maneira rápida?
Em um mundo tão rápido e tecnológico ninguém quer perder tempo e convenhamos que isso nem deve acontecer.
O foco desse artigo é dar algumas dicas de como podemos identificar e solucionar os problemas de consultas demoradas ao banco.
Quando o nosso problema de performance é lógico e não de ambiente (infra estrutura) na maioria dos casos conseguimos resolver com a criação de índices em uma coluna na nossa tabela no banco de dados.
Pensamos da seguinte maneira: à medida que inserimos, atualizamos ou deletamos dados de uma tabela, estamos alterando os espaços do disco de memória, que não consegue ter uma padrão de tamanho ou sequência, nossos dados ficam espalhados e quando fazemos uma busca é preciso acessar vários lugares diferentes.
Quando fazemos uma consulta sem índice é preciso que percorra todos os lugares da memória para encontrar o que estamos buscando, mesmo que tenham filtros na cláusula where.
Mas então como os índices funcionam?
Os índices tem por padrão serem do tipo B tree, que nada mais é que uma árvore de informações. Acredito que muitas pessoas tenham visto na faculdade o formato de árvore para estrutura de dados, onde é separado o menor valor a esquerda e o maior à direita.
Para entendermos melhor vou mostrar um exemplo:


Essa consulta teria que percorrer os oito espaços da memória para encontrar o resultado desejado, então é como se fizesse oito perguntas ao banco.
Mesmo que encontre um funcionário camila antes de percorrer todos os espaços, ainda precisa continuar procurando para ver se não possui mais nenhum funcionário com este nome.
O que aconteceria se nós criarmos um índice btree para a coluna nome?

Ele teria criado uma árvore com os nossos dados:
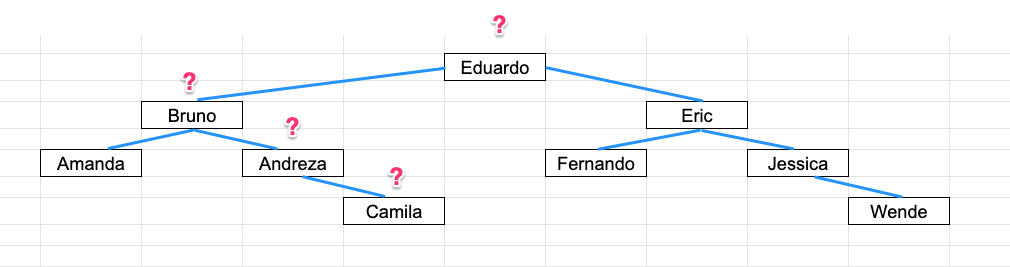
Percebam que ao percorrer a nossa árvore o número de perguntas ao banco diminui em menos da metade, antes tínhamos que fazer nove perguntas até chegar ao resultado desejado e isso foi otimizado para quatro perguntas. Agora imagine isso com um volume grande de dados, faz toda a diferença.
Entendemos o que é o tree do nosso padrão de criação de índice B-tree, mas de onde vem o B?
Nada mais é do que a abreviação da palavra em inglês balance(equilíbrio), ou seja, a nossa árvore é sempre balanceada, ela sabe sozinha como se estruturar de maneira que os dados não fiquem somente em um galho (lado), conforme atualizamos a nossa tabela a árvore de índices se reestrutura.
E como tudo que fazemos sempre tem alguma consequência, com esse balanceamento na estrutura da árvore isso nos custa um tempo maior em inserções, exclusões e atualizações (comandos DML), então não é bom ficar criando índices de todos os campos de uma tabela e sim do que realmente precisamos.
Agora vamos ver alguns exemplos que irão nos mostrar como as chaves primárias/estrangeiras e um índice conseguem otimizar as nossas consultas, mensurando pelo plano de explicação.
Uma dica legal é que toda query que montamos tem um plano de execução (explain plan) onde possui informações importantes como o custo, forma de acesso à uma tabela, entre outras informações. Por tanto, existem outras formas de medir a eficácia de uma query além do seu tempo de execução.
Exemplo tabela Heap:
Uma tabela que pode ser chamada de heap são todas aquelas que não possuem nenhum índice e também não possuem chaves primárias ou estrangeiras. Qualquer consulta que fazemos em uma tabela heap fazendo a junção dela com outras ou inserindo cláusulas no where é mais custosa comparada com tabelas que não são.

No exemplo acima do plano de execução da nossa query o custo tem valor de dez e todas as tabelas no select tem acesso full.
Exemplo tabela relacional sem indice:
As tabelas relacionais são tabelas que possuem relação uma com as outras através de chaves estrangeiras.

No exemplo acima do plano de execução da nossa query o custo tem valor de cinco e somente a tabela funcionario_teste tem acesso full.
Exemplo tabela relacional com índice:
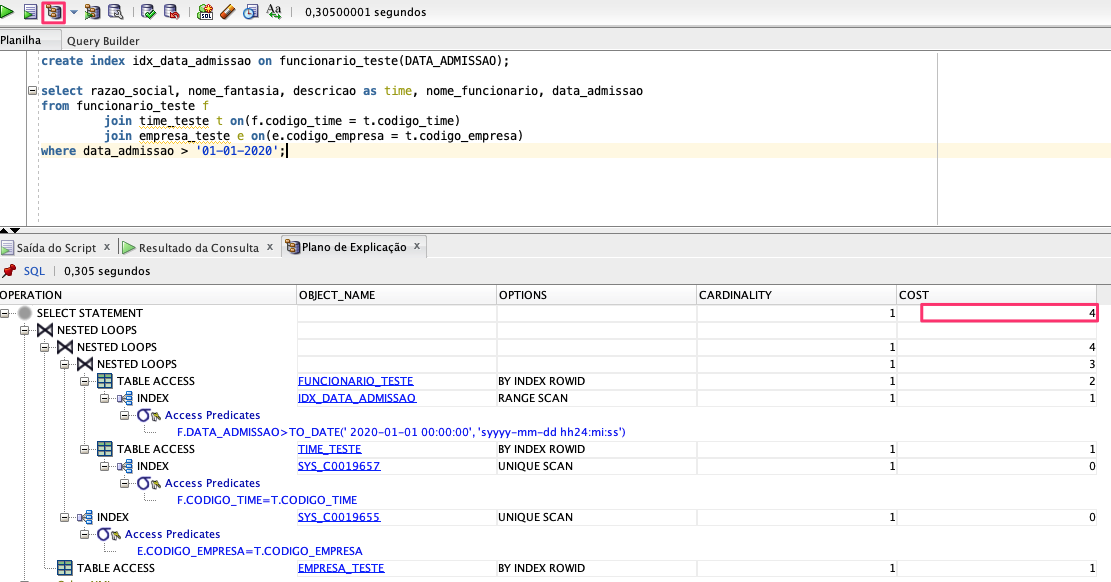
No exemplo acima do plano de explicação da nossa query o custo tem valor de quatro e nenhuma tabela tem acesso full.
Com simples exemplos com volume mínimo de dados vemos o quanto criar relações corretas de chaves primárias e estrangeiras e criar índices diminui significamente o custo de uma query.
No nosso dia-a-dia o volume de dados e a complexidade das nossas consultas (queries) são muito maiores, por isso não podemos perder tempo, esperando que os usuários nos alertem sobre tempo grande de espera ou impossibilidade de visualizar um relatório. É claro que existem outras maneiras maiores e talvez até melhores além dessas dicas citadas no artigo mas sabendo coisas simples como o executar um plano de execução (explain plan) e como criar índices já conseguimos melhorar significativamente a performance das nossas consultas.
Referências:
https://cursos.alura.com.br/course/oracle-database-desempenho-sql
https://www.devmedia.com.br/entendendo-e-usando-indices/6567
https://blogs.oracle.com/sql/how-to-create-and-use-indexes-in-oracle-database





1 Comentário
Olá Camila, post muito legal, sou iniciante e gostaria de saber se tem como verificar quais tabelas precisam de índices, no sql server tem alguns postes que mostram querys para identificar índices faltantes em um datafile, pode me ajudar?
Parabéns pelo post, já estou usando.